LiteLLM analytics installation
Note: LiteLLM can be used as a Python SDK or as a proxy server. PostHog observability requires LiteLLM version 1.77.3 or higher.
- 1
Install LiteLLM
RequiredChoose your installation method based on how you want to use LiteLLM:
- 2
Configure PostHog observability
RequiredConfigure PostHog by setting your project API key and host as well as adding
posthogto your LiteLLM callback handlers. You can find your API key in your project settings. - 3
Call LLMs through LiteLLM
RequiredNow, when you use LiteLLM to call various LLM providers, PostHog automatically captures an
$ai_generationevent.Notes:
- This works with streaming responses by setting
stream=True. - To disable logging for specific requests, add
{"no-log": true}to metadata. - If you want to capture LLM events anonymously, don't pass a
user_idin metadata. See our docs on anonymous vs identified events to learn more.
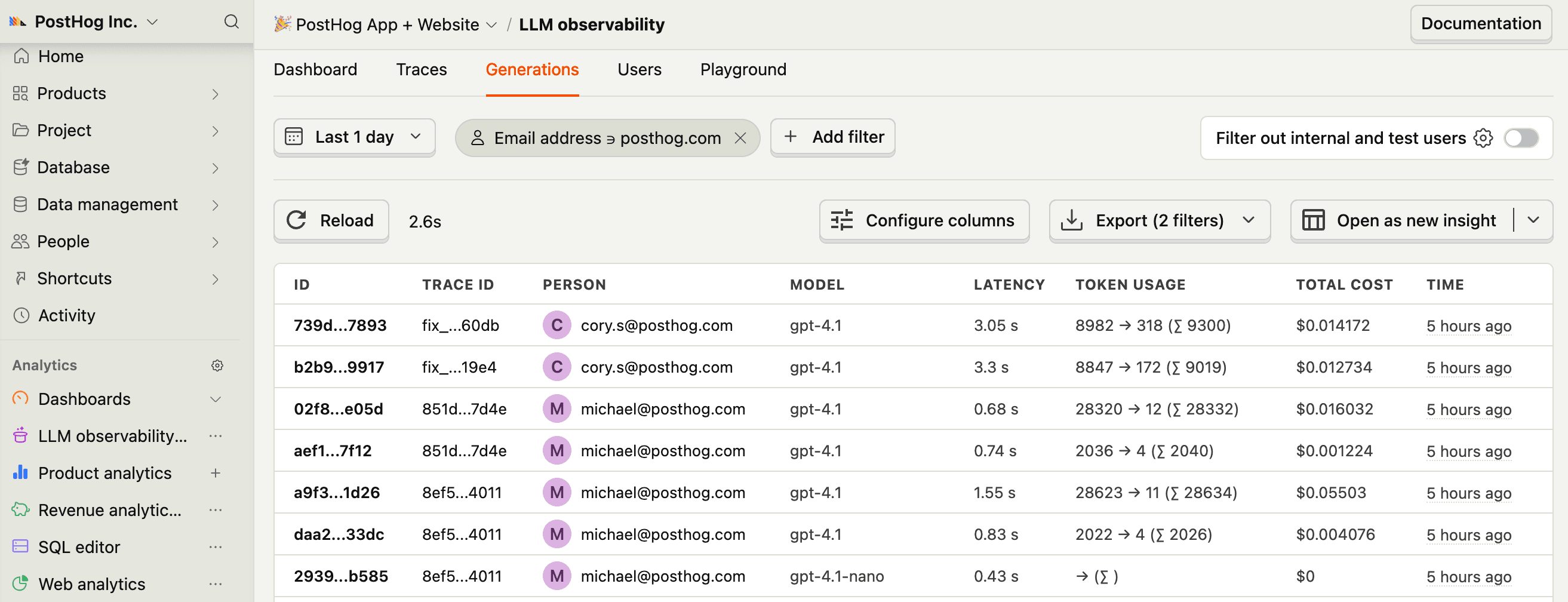
You can expect captured
$ai_generationevents to have the following properties:Property Description $ai_modelThe specific model, like gpt-5-miniorclaude-4-sonnet$ai_latencyThe latency of the LLM call in seconds $ai_toolsTools and functions available to the LLM $ai_inputList of messages sent to the LLM $ai_input_tokensThe number of tokens in the input (often found in response.usage) $ai_output_choicesList of response choices from the LLM $ai_output_tokensThe number of tokens in the output (often found in response.usage)$ai_total_cost_usdThe total cost in USD (input + output) ... See full list of properties - This works with streaming responses by setting
- 5
Capture embeddings
OptionalPostHog can also capture embedding generations as
$ai_embeddingevents through LiteLLM: